Java关键字学习(更新中)
1.assert jdk1.4
assert意为断言的意思,这个关键字可以判断布尔值的结果是否和预期的一样,如果一样就正常执行,否则会抛出AssertionError。
assert有两种用法:
(1)asset expression1;
(2)asset expression1 : expression2; // expression2允许我们自定义一个异常错误信息抛出。
注意,在运行的时候,正常情况下assert是不会生效的,因为运行时assert是关闭的,想要使用,必须在VM启动参数中开启:
-enableassertions 或者 -ea
即使assert能够精简的判断一些case,并不推荐在生产环境中使用,因为在运行时默认是关闭assert的,因为开启assert校验,也会损耗一定的性能,并且如果在关键部分的校验使用了assert验证,但是忘记开启assert功能,那么肯定会造成重大的失误,所以一般都是在测试类里面使用的比较多。
那么,既然没法在生产环境中使用assert功能,那么有没有替代的assert的组件?
替代assert的组件
(1)在spring环境中,可以直接使用工具类Assert:
Assert.notNull(obj, "object was null");(2)如果不在spring中,在普通的Java项目中可以使用jdk7中自带的Objects工具类:
Objects.requireNonNull()(3)如果觉得Objects工具类功能较弱,可以引入junit工具类里面的Assert类:
Assert.assertNotNull();2.transient
让某些被修饰的成员属性变量不被序列化
注:
- 只能修饰变量,而不能修饰方法和类
- 一个静态变量不管是否被transient修饰,均不能被序列化
使用情况:
1、类中的字段值可以根据其它字段推导出来,那么在序列化的时候,面积这个属性就没必要被序列化了
2、具体业务需求不需要其被序列化
注意:
HashMap中的桶数组 table 被申明为 transient。table 如果不序列化的话,怎么传输并还原呢?(HashSet同理)
HashMap 并没有使用默认的序列化机制,而是通过实现
readObject/writeObject两个方法自定义了序列化的内容。直接序列化 talbe 存在着两个问题:
- table 多数情况下是无法被存满的,序列化未使用的部分,浪费空间
- 同一个键值对在不同 JVM 下,所处的桶位置可能是不同的,在不同的 JVM 下反序列化 table 可能会发生错误。
以上两个问题中,第一个问题比较好理解,第二个问题解释一下。HashMap 的
get/put/remove等方法第一步就是根据 hash 找到键所在的桶位置,但如果键没有覆写 hashCode 方法,计算 hash 时最终调用 Object 中的 hashCode 方法。但 Object 中的 hashCode 方法是 native 型的,不同的 JVM 下,可能会有不同的实现,产生的 hash 可能也是不一样的。也就是说同一个键在不同平台下可能会产生不同的 hash,此时再对在同一个 table 继续操作,就会出现问题。
在Java中,对象的序列化可以通过实现两种接口来实现,若实现的是Serializable接口,则所有的序列化将会自动进行,若实现的是Externalizable接口,则没有任何东西可以自动序列化,需要在writeExternal方法中进行手工指定所要序列化的变量,这与是否被transient修饰无关。
3.native
用来修饰方法,代表该方法是在用其他语言(如C和C++)实现的文件中,并不提供实现体
标识符native可以与所有其它的java标识符连用,但是abstract除外。这是因为native暗示这些方法是有实现体的,只不过这些实现体是非java的,但是abstract却显然的指明这些方法无实现体。
native method方法可以返回任何java类型,包括非基本类型,而且同样可以进行异常控制。这些方法的实现体可以自制一个异常并且将其抛出,这一点与java的方法非常相似。
native method的存在并不会对其他类调用这些本地方法产生任何影响,实际上调用这些方法的其他类甚至不知道它所调用的是一个本地方法。JVM将控制调用本地方法的所有细节。 如果一个含有本地方法的类被继承,子类会继承这个本地方法并且可以用java语言重写这个方法(这个似乎看起来有些奇怪),同样的如果一个本地方法被fianl标识,它被继承后不能被重写。
本地方法非常有用,因为它有效地扩充了JVM。事实上,我们所写的java代码已经用到了本地方法,在sun的java的并发(多线程)的机制实现中,许多与操作系统的接触点都用到了本地方法,这使得java程序能够超越java运行时的界限。有了本地方法,java程序可以做任何应用层次的任务。
大致使用步骤:
在Java中声明native()方法,然后编译;
用javah产生一个.h文件;
写一个.cpp文件实现native导出方法,其中需要包含第二步产生的.h文件(注意其中又包含了JDK带的jni.h文件);
将第三步的.cpp文件编译成动态链接库文件;
在Java中用System.loadLibrary()方法加载第四步产生的动态链接库文件,这个native()方法就可以在Java中被访问了。
4.volatile
用来修饰变量,表示该变量为共享变量,不会将该变量上的操作与其他内存操作一起重排序
Java语言提供了一种稍弱的同步机制,即volatile变量,用来确保将变量的更新操作通知到其他线程。当把变量声明为volatile类型后,编译器与运行时都会注意到这个变量是共享的,因此不会将该变量上的操作与其他内存操作一起重排序。volatile变量不会被缓存在寄存器或者对其他处理器不可见的地方,因此在读取volatile类型的变量时总会返回最新写入的值。
在访问volatile变量时不会执行加锁操作,因此也就不会使执行线程阻塞,因此volatile变量是一种比sychronized关键字更轻量级的同步机制。
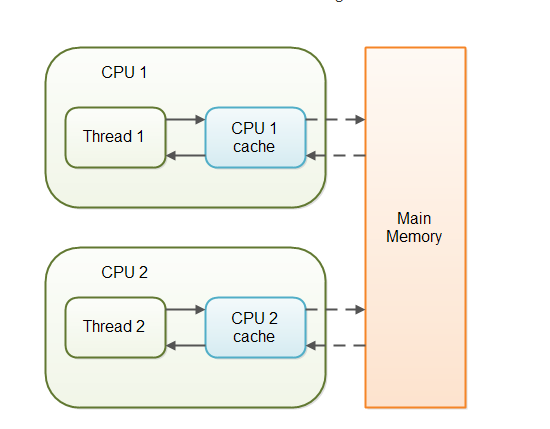
当对非 volatile 变量进行读写的时候,每个线程先从内存拷贝变量到CPU缓存中。如果计算机有多个CPU,每个线程可能在不同的CPU上被处理,这意味着每个线程可以拷贝到不同的 CPU cache 中。
而声明变量是 volatile 的,JVM 保证了每次读变量都从内存中读,跳过 CPU cache 这一步。
当一个变量定义为 volatile 之后,将具备两种特性:
- 保证此变量对所有的线程的可见性,也就是当一个线程修改了这个变量的值,volatile 保证了新值能立即同步到主内存,以及每次使用前立即从主内存刷新。但普通变量做不到这点,普通变量的值在线程间传递均需要通过主内存(详见:Java内存模型)来完成。
- 禁止指令重排序优化。有volatile修饰的变量,赋值后多执行了一个“load addl $0x0, (%esp)”操作,这个操作相当于一个内存屏障(指令重排序时不能把后面的指令重排序到内存屏障之前的位置),只有一个CPU访问内存时,并不需要内存屏障;(指令重排序:是指CPU采用了允许将多条指令不按程序规定的顺序分开发送给各相应电路单元处理)。
volatile 性能:
volatile 的读性能消耗与普通变量几乎相同,但是写操作稍慢,因为它需要在本地代码中插入许多内存屏障指令来保证处理器不发生乱序执行
.png)