MySQL——连接原理
用到的表结构
mysql> SELECT * FROM t1;
+------+------+
| m1 | n1 |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
+------+------+
3 rows in set (0.00 sec)
mysql> SELECT * FROM t2;
+------+------+
| m2 | n2 |
+------+------+
| 2 | b |
| 3 | c |
| 4 | d |
+------+------+
3 rows in set (0.00 sec)1.嵌套循环连接(Nested-Loop Join)
对于两表连接来说,驱动表只会被访问一遍,但被驱动表却要被访问到好多遍,具体访问几遍取决于对驱动表执行单表查询后的结果集中的记录条数。对于内连接来说,选取哪个表为驱动表都没关系,而外连接的驱动表是固定的,也就是说左(外)连接的驱动表就是左边的那个表,右(外)连接的驱动表就是右边的那个表。
t1表和t2表执行内连接查询的大致过程:
- 步骤1:选取驱动表,使用与驱动表相关的过滤条件,选取代价最低的单表访问方法来执行对驱动表的单表查询。
- 步骤2:对上一步骤中查询驱动表得到的结果集中每一条记录,都分别到被驱动表中查找匹配的记录。
通用的两表连接过程如下图所示:
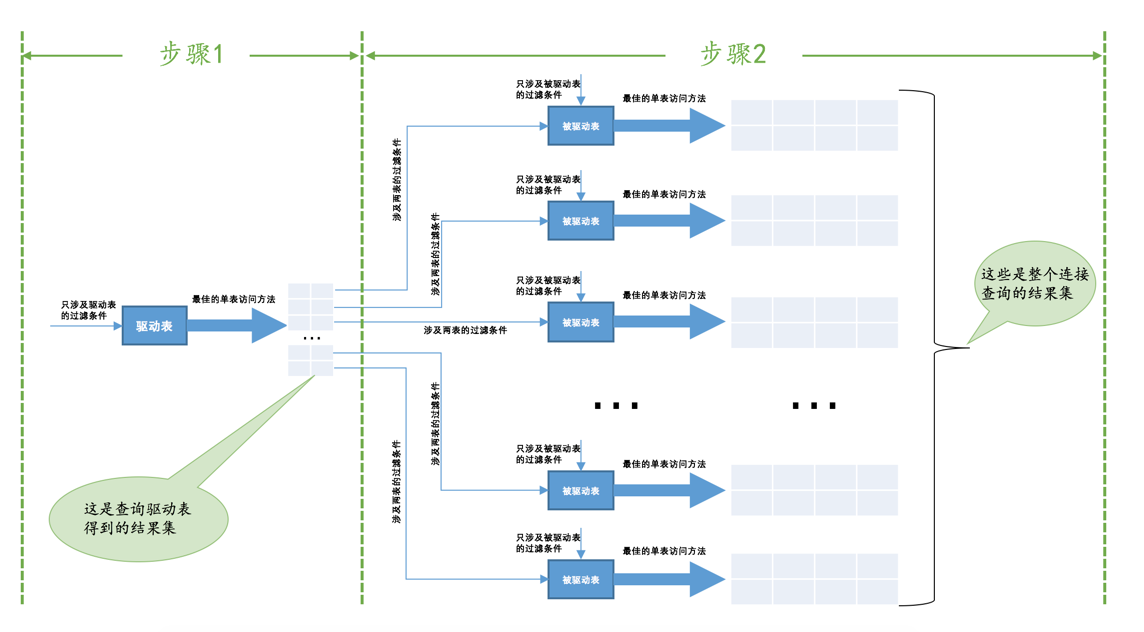
如果有3个表进行连接的话,那么步骤2中得到的结果集就像是新的驱动表,然后第三个表就成为了被驱动表,重复上面过程,也就是步骤2中得到的结果集中的每一条记录都需要到t3表中找一找有没有匹配的记录,用伪代码表示一下这个过程就是这样:
for each row in t1 { #此处表示遍历满足对t1单表查询结果集中的每一条记录
for each row in t2 { #此处表示对于某条t1表的记录来说,遍历满足对t2单表查询结果集中的每一条记录
for each row in t3 { #此处表示对于某条t1和t2表的记录组合来说,对t3表进行单表查询
if row satisfies join conditions, send to client
}
}
} 这个过程就像是一个嵌套的循环,所以这种驱动表只访问一次,但被驱动表却可能被多次访问,访问次数取决于对驱动表执行单表查询后的结果集中的记录条数的连接执行方式称之为嵌套循环连接(Nested-Loop Join),这是最简单,也是最笨拙的一种连接查询算法。
2.使用索引加快连接速度(Index Nested-Loop Join (INLJ))
利用索引在嵌套循环连接的步骤2中加快查询速度。回顾一下t1表和t2`表进行内连接的例子:
SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < 'd'; 使用的其实是嵌套循环连接算法执行的连接查询,再把上面那个查询执行过程表拉下来给大家看一下:
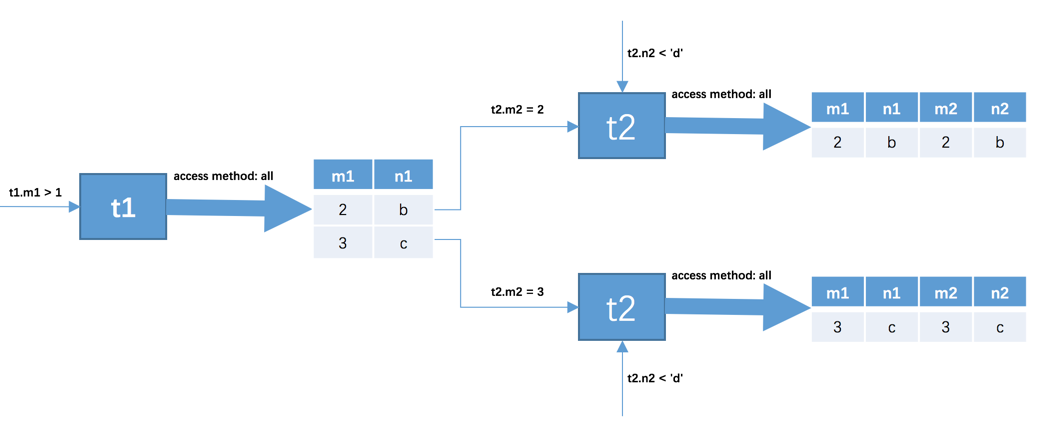
查询驱动表t1后的结果集中有两条记录,嵌套循环连接算法需要对被驱动表查询2次:
当
t1.m1 = 2时,去查询一遍t2表,对t2表的查询语句相当于:SELECT * FROM t2 WHERE t2.m2 = 2 AND t2.n2 < 'd';当
t1.m1 = 3时,再去查询一遍t2表,此时对t2表的查询语句相当于:SELECT * FROM t2 WHERE t2.m2 = 3 AND t2.n2 < 'd';
可以看到,原来的t1.m1 = t2.m2这个涉及两个表的过滤条件在针对t2表做查询时关于t1表的条件就已经确定了,所以我们只需要单单优化对t2表的查询了,上述两个对t2表的查询语句中利用到的列是m2和n2列,那么就可以:
在
m2列上建立索引,因为对m2列的条件是等值查找,比如t2.m2 = 2、t2.m2 = 3等,所以可能使用到ref的访问方法,假设使用ref的访问方法去执行对t2表的查询的话,需要回表之后再判断t2.n2 < d这个条件是否成立。这里有一个比较特殊的情况,就是假设
m2列是t2表的主键或者唯一二级索引列,那么使用t2.m2 = 常数值这样的条件从t2表中查找记录的过程的代价就是常数级别的。我们知道在单表中使用主键值或者唯一二级索引列的值进行等值查找的方式称之为const,而设计MySQL的大佬把在连接查询中对被驱动表使用主键值或者唯一二级索引列的值进行等值查找的查询执行方式称之为:eq_ref。在
n2列上建立索引,涉及到的条件是t2.n2 < 'd',可能用到range的访问方法,假设使用range的访问方法对t2表的查询的话,需要回表之后再判断在m2列上的条件是否成立。
假设m2和n2列上都存在索引的话,那么就需要从这两个里边儿挑一个代价更低的去执行对t2表的查询。当然,建立了索引不一定使用索引,只有在二级索引 + 回表的代价比全表扫描的代价更低时才会使用索引。
另外,有时候连接查询的查询列表和过滤条件中可能只涉及被驱动表的部分列,而这些列都是某个索引的一部分,这种情况下即使不能使用eq_ref、ref、ref_or_null或者range这些访问方法执行对被驱动表的查询的话,也可以使用索引扫描,也就是index的访问方法来查询被驱动表。所以建议在真实工作中最好不要使用*作为查询列表,最好把真实用到的列作为查询列表。
3.基于块的嵌套循环连接(Block Nested-Loop Join)
内存里可能并不能完全存放的下表中所有的记录,所以在扫描表前面记录的时候后边的记录可能还在磁盘上,等扫描到后边记录的时候可能内存不足,所以需要把前面的记录从内存中释放掉。我们前面又说过,采用嵌套循环连接算法的两表连接过程中,被驱动表可是要被访问好多次的,如果这个被驱动表中的数据特别多而且不能使用索引进行访问,那就相当于要从磁盘上读好几次这个表,这个I/O代价就非常大了,所以我们得想办法:尽量减少访问被驱动表的次数。
当被驱动表中的数据非常多时,每次访问被驱动表,被驱动表的记录会被加载到内存中,在内存中的每一条记录只会和驱动表结果集的一条记录做匹配,之后就会被从内存中清除掉。然后再从驱动表结果集中拿出另一条记录,再一次把被驱动表的记录加载到内存中一遍,周而复始,驱动表结果集中有多少条记录,就得把被驱动表从磁盘上加载到内存中多少次。所以我们可不可以在把被驱动表的记录加载到内存的时候,一次性和多条驱动表中的记录做匹配,这样就可以大大减少重复从磁盘上加载被驱动表的代价了。所以设计MySQL的大佬提出了一个join buffer的概念,join buffer就是执行连接查询前申请的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个join buffer中,然后开始扫描被驱动表,每一条被驱动表的记录一次性和join buffer中的多条驱动表记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的I/O代价。使用join buffer的过程如下图所示:
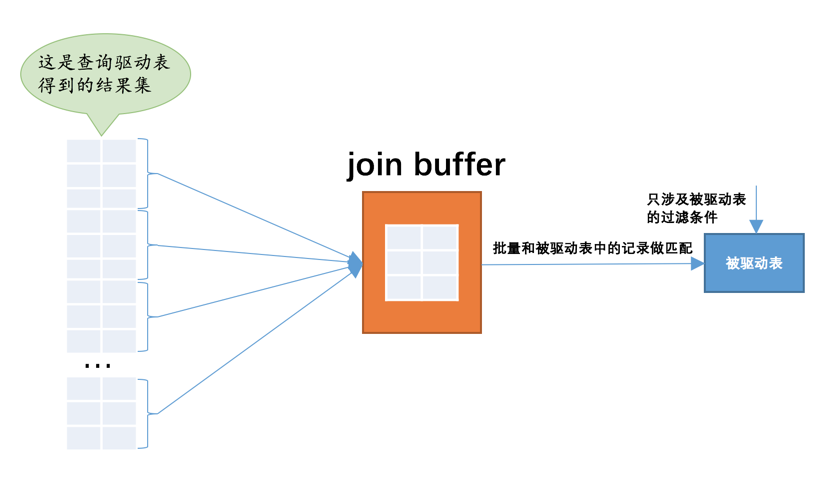
最好的情况是join buffer足够大,能容纳驱动表结果集中的所有记录,这样只需要访问一次被驱动表就可以完成连接操作了。设计MySQL的大佬把这种加入了join buffer的嵌套循环连接算法称之为基于块的嵌套连接(Block Nested-Loop Join)算法。
这个join buffer的大小是可以通过启动参数或者系统变量join_buffer_size进行配置,默认大小为262144字节(也就是256KB),最小可以设置为128字节。当然,对于优化被驱动表的查询来说,最好是为被驱动表加上效率高的索引,如果实在不能使用索引,并且自己的机器的内存也比较大可以尝试调大join_buffer_size的值来对连接查询进行优化。
另外需要注意的是,驱动表的记录并不是所有列都会被放到join buffer中,只有查询列表中的列和过滤条件中的列才会被放到join buffer中,所以再次提醒我们,最好不要把*作为查询列表,只需要把我们关心的列放到查询列表就好了,这样还可以在join buffer中放置更多的记录呢。
完整文章为:《MySQL 是怎样运行的:从根儿上理解 MySQL》——第11章 两个表的亲密接触-连接的原理
.png)